Structure 6.3 Release Notes
8th of October, 2020
Structure 6.3 adds the Status Rollup Effector, default views, Project Category grouper and more.
Download the latest version of Structure and its Extensions
Try It: Structure Sandbox Server (no installation required)
Version Highlights
Structure 6.3 adds:
- Status Rollup Effector
- Default view for structures
- Group by Project Category
- Improved Information Center
- Ability to edit numeric custom fields through Structure Gadget
- Additional improvements
Changes in Detail
Status Rollup Effector
This new effector allows you to automatically update parent issue statuses based on the earliest status of their sub-issues.
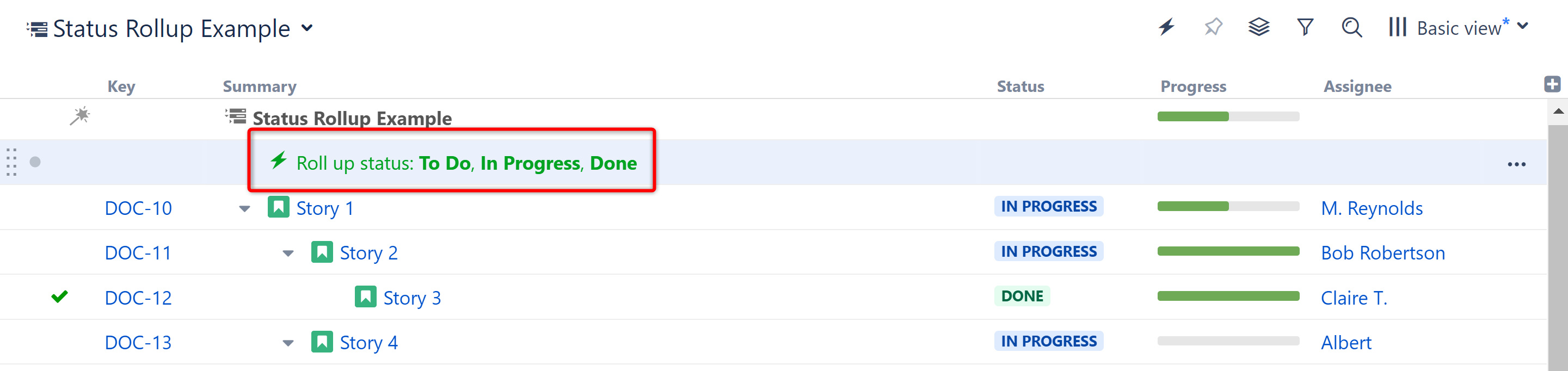
Documentation: Status Rollup Effector
Default Views
It is now possible to select a default view for each structure right from the Views menu. When set, users who open the structure for the first time will see the default view. Additionally, if there is no recently-selected view available for the structure, it will open with the default view.
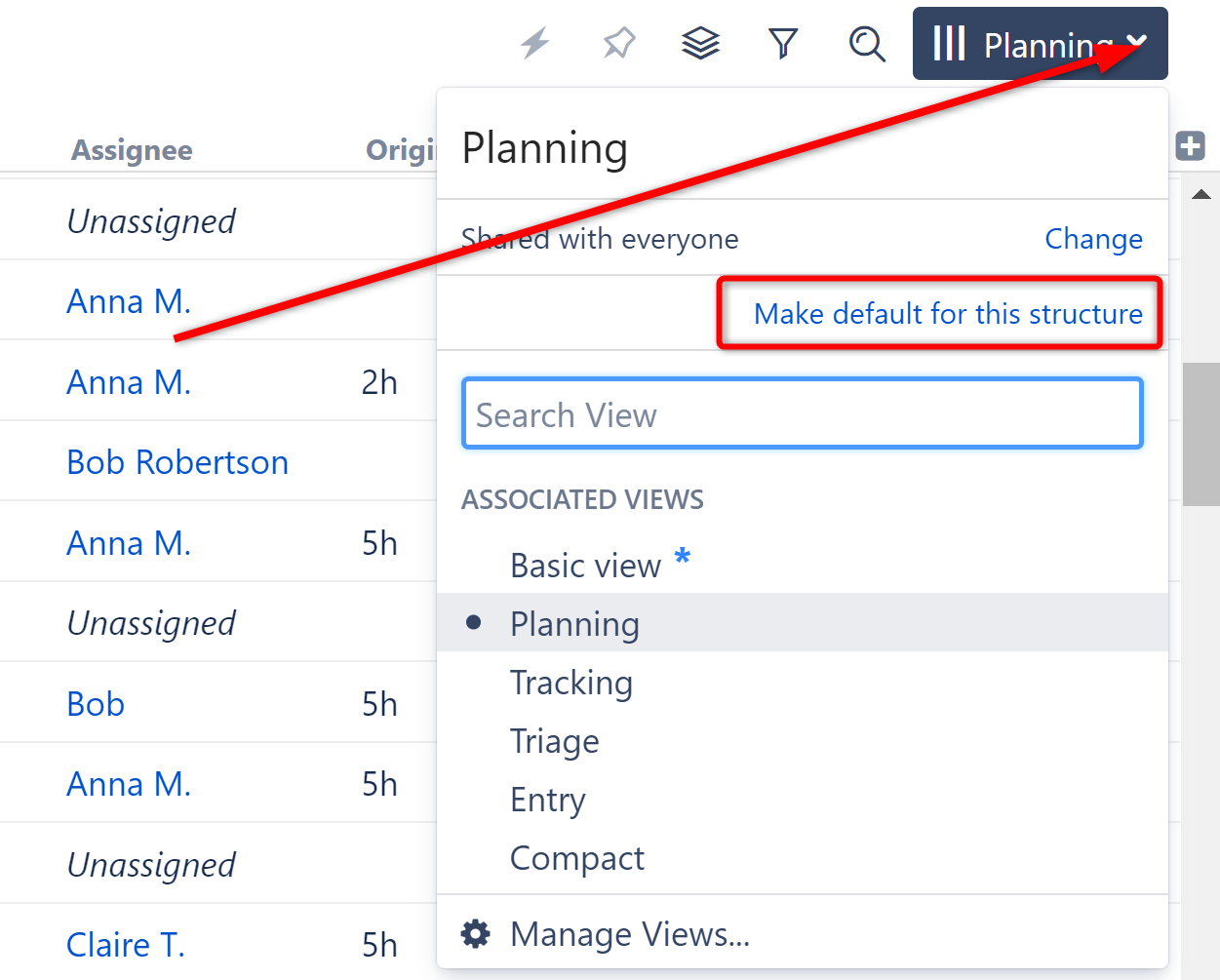
Documentation: Views Menu
Group by Project Category and ScriptRunner Single Issue Picker
It is now possible to group items by Project Category and the ScriptRunner Single Issue Picker field, using Group Automation.
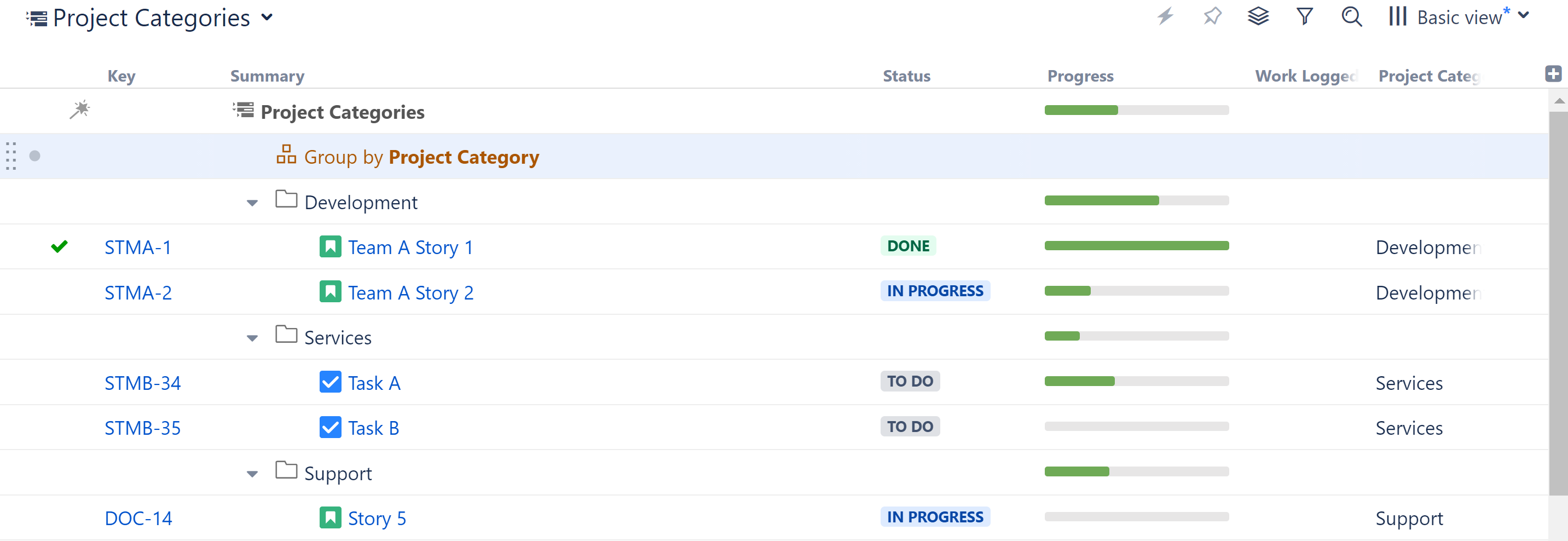
To Group by Project Category, select Automation | Group by Text Attribute, and then select Group by Project Category. If you have ScriptRunner installed and have defined Single Issue Pickers, they will appear under the Automation | Group by... menu.
- Project Category and the ScriptRunner Picker field can also be added as Structure columns and used in formulas.
ScriptRunner Picker values can be updated within the structure by dragging an issue to another group or using inline editing (when added as a column).
Documentation: Group Generators, ScriptRunner
Improved Information Center
The improved Info window now includes additional links and information about Structure extensions.
Additional Updates
- Structure now remembers the last view used with each structure, and returns to that view the next time the structure is opened.
- A new hotkey ('vvv') returns to the previous view.
- It is now impossible to edit gadget in Confluence.
- It is now possible to update numeric fields in the Dashboard gadget.
- It is now possible to include the backlog when using the Sprint Filter Transformation.
- Query Match is now a resizable field in Structure formulas.
- Attribute system now reads the values of numeric, date, and date-time custom fields from the Lucene index. Learn more.
- Fixed: Data was lost when saving changes to a Memo.
- Fixed: Confluence gadget displayed values unrelated to the displayed structure. Learn more.
- Fixed: Export failed due to Lock Timeout on busy systems. Learn more.
Supported Versions
Structure 6.3 and all extensions support Jira versions 7.13 or later. This release is for customers using Jira Server or Data Center (Jira Core, Jira Software, or Jira Service Desk).
Compatible plugins versions:
- Structure.Gantt 2.4+
- Structure.Pages 1.5+
- Structure.Testy 2.4+
Cloud customers can learn more about our products on the “Cloud” tab of our marketplace listing.
Installation and Upgrade
Pick a Time
We strongly recommend that you install and upgrade your apps during off-peak hours or scheduled maintenance windows. There are known issues in the Jira plugin infrastructure that may cause performance degradation and impede app installation when your Jira instance is under heavy load.
Installing Structure
If your Jira server does not have Structure yet, the installation is simple:
- Download and install Structure app, either from the Atlassian Marketplace or our Download page.
- When Add-on Manager reports the successful installation, click Get Started to visit a page with important guidance for the Jira administrator. You may want to also check out the user's Get Started page, available under the "Structure" top-level menu.
- Monitor
catalina.outorjira-application.logfor log messages from Structure.
Upgrading Structure
The upgrade procedure from versions 3.0–6.2 is simple:
- Consider backing up Jira data. Use Administration | System | Backup System. (If you have a large instance and a proper backup strategy in place, you may skip this step.)
- Back up Structure data. Use Administration | Structure | Backup Structure menu item. If you have a lot of structures and a large Jira, consider turning off the "Backup History" option to avoid a long backup process.
Install the new version of the plugin.
- Monitor
catalina.outorjira-application.logfor warnings or errors.
Upgrading from Structure 2.9–2.11
If you have a Structure version older than 2.9, please upgrade to Structure 2.11.2 version first.
Starting with version 6.0, Structure is no longer able to access the old Structure 2.x database, but old backup files are still supported. Therefore, you'll need to back up your Structure 2.x data before upgrading. The recommended upgrade procedure is as follows:
- While still running the old version of Structure, go to Administration | Structure | Structure Backup and create a backup of the current Structure data.
- Download and install Structure 6.0, either from the Atlassian Marketplace or our Download page.
- When the Add-on Manager reports the successful installation, click Get Started to visit a page with important guidance for the Jira administrator. You may want to also check out the Getting Started with Structure.
To transfer your data, go to Administration | Structure | Restore Structure and use the Structure 2.x backup made earlier.
- Monitor
catalina.outorjira-application.logfor log messages from Structure.
Enterprise Deployment Notes
Structure 6.3 introduces a few changes and improvements especially important for large-scale Jira Server and Jira Data Center instances.
Reading Custom Fields from the Index
Starting with Structure 6.3, the attribute system reads the values of numeric, date, and date-time custom fields from the Lucene index instead of the database. Reading a single field for many issues from the index is usually much faster than loading a lot of issue objects one by one from the database. Structure generators have been using this technique for a long time, and now we're bringing it to the attribute subsystem.
This improvement is especially important for aggregate values like sums, where Structure sometimes needs to load the values for many more issues than the user sees on the screen to calculate the sum. If you have big structures with thousands of issues and you calculate aggregates based on numeric, date and date-time custom fields on those structures, we advise that you verify the performance of those aggregate columns in a staging environment before upgrading.
Cluster Node Tracking in Structure Gadget in Confluence
The Structure gadget, unlike most other Jira gadgets, is a live web application, and it uses multiple REST requests to load the data and keep it up-to-date. When a Structure gadget is inside a Confluence page, those REST requests have to be proxied by Confluence: the gadget calls Confluence, which then calls Jira and forwards its reply back to the gadget. For each forwarded request, Confluence authenticates the current user, creating a new, single-use user session. In a Jira Data Center instance, the load balancer can route these requests to different cluster nodes, so it is possible, for example, that the gadget loads the structure from one node, but the values shown in the grid come from a different node.
Structure was not designed to operate in these conditions. This problem was hard to notice in earlier versions of Structure, but since Structure 6.0, completely unrelated values may be shown in the grid, giving the illusion that a different structure is displayed.
In Structure 6.3, we've updated the gadget to keep track of the cluster node: it remembers the node from which it received its first reply, and if later a reply comes from a different node, the gadget will ignore it and retry the request, hoping that the load balancer will redirect it to the original node. If the gadget is unable to reach the original node after multiple attempts, it will stop updating the data and display an error message. If the original node is down, reloading the page will reinitialize the gadget and "bind" it to a different node.
Also, the gadget will always switch to read-only mode if it's on a Confluence page and the Jira instance is a Data Center instance. This solution is only a temporary workaround. We are still researching better ways of integrating Structure into Confluence pages.
More Reliable Export Under Load
We have seen a few cases where, on a busy system, exporting a structure to an Excel file or printable HTML would fail due to a lock timeout because the exporting thread would not be able to lock and refresh the structure for 30 seconds. Users would then have to retry or, in the most extreme cases, schedule their exports during a quiet period.
In Structure 6.3, we've made the export process more robust: it will now wait for at least 10 minutes to let the other threads finish and get access to the structure. Also, after 2 minutes of waiting time, the exporter will try to switch to a "fast path": if there's already a recent version of this structure in the cache, it will be exported without waiting for the lock (accompanied by a warning that the exported version may be outdated). We hope that these changes improve users' experience when exporting large, complex structures under heavy load.
Testing on Staging Environment
Apart from the changes and suggestions above, there are no particular special areas of interest for load testing and stress testing Structure 6.3. We advise running the same testing procedures as you've done for previous upgrades.