Structure 6.0 Release Notes
26th of March, 2020
Structure 6 adds Effectors, user-based permissions, and API changes.
Download the latest version of Structure and its Extensions
Try It: Structure Sandbox Server (no installation required)
Version Highlights
- Effectors - a new form of automation for writing Structure attributes to Jira fields
- Possibility to define permissions per user
- API changes that may affect Structure integrations
- Attribute sensitivity settings
- Improved rank sorting
Changes in Detail
Effectors
The Attribute to Issue Field Effector allows you to write the values from Structure attributes (formulas, structure-specific columns, Structure.Gantt attributes, etc.) to Jira issue fields.
For more information, see our Effectors documentation and check out these sample use cases:
- Calculate Epic Story Points Based on Sub-issues
- Update Assignees to Match Parent Issues
- Calculate the Cost to Complete Issues and Projects - and Write Those Costs to Jira
Permissions Per User
It is now possible to assign structure permissions to specific users. Previously permissions could only be set based on user groups or project teams.

Documentation: Structure Permissions
API Changes
Structure 6 introduces significant changes to Java API. (REST API remains backwards compatible.) The changes are called for because of a large remake of the attributes subsystem in the product.
If you have an integration or an extension of Structure, your code might break. More specifically:
- If you're creating your own attribute loaders, your code will definitely be incompatible and will need some work.
- If you're just using the attribute subsystem, such as
StructureAttributeService, your code may well break, but fixing it will most likely be trivial. - If you're using REST APIs or other parts of Structure API, your code is very unlikely to stop working.
For more specifics about these API changes, see Structure 6 API Changes.
Attribute Sensitivity Settings
Attribute sensitivity settings provide a new level of data security within Structure, allowing admins to specify fields that may contain sensitive information and, therefore, should not be included when calculating aggregated functions.
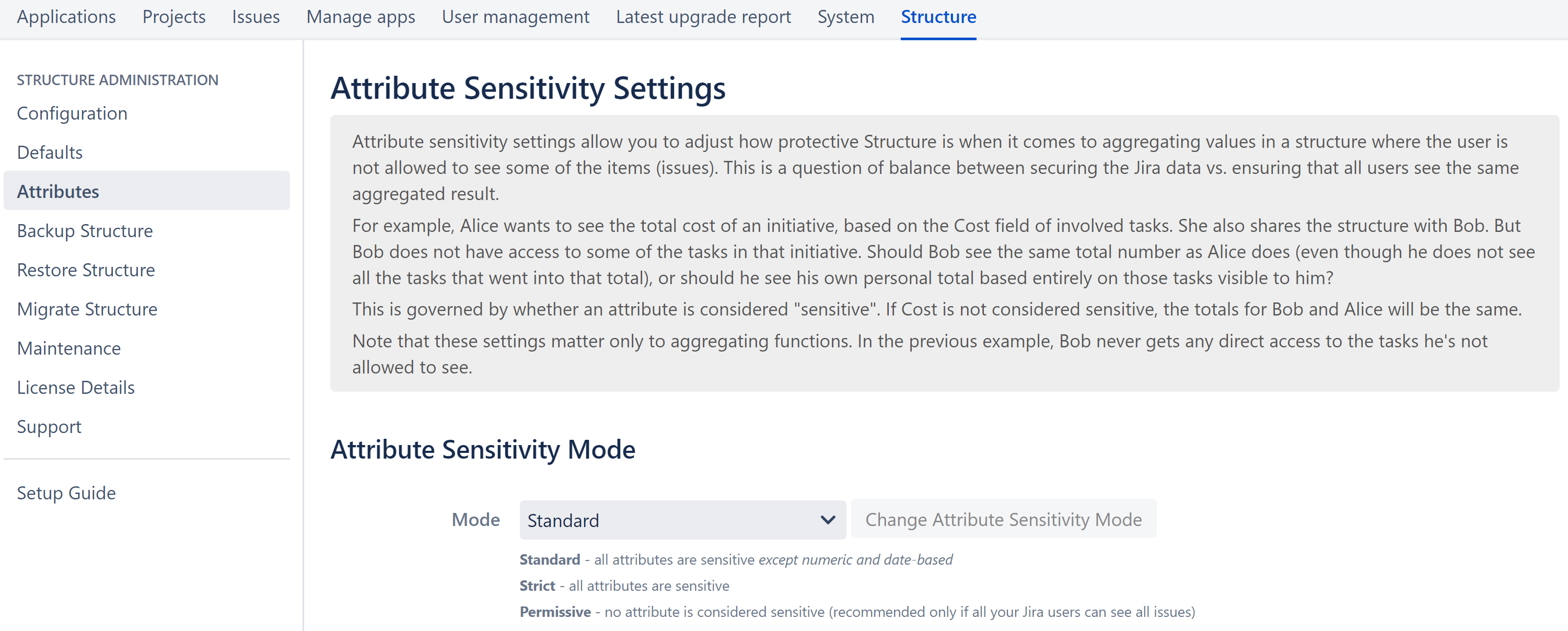
Documentation: Attribute Sensitivity Settings
Improved Rank Sorting
When items are sorted by rank, sub-issues now appear beneath their parent items.
Supported Versions
Structure 6.0 and all extensions support Jira versions 7.13 or later. All editions of Jira (Jira Core, Jira Software, Jira Service Desk) are supported. Jira Data Center is supported.
Compatible plugins versons:
- Structure.Gantt 2.3
- Structure.Pages, 1.5
- Structure.Testy 2.4
Installation and Upgrade
Pick a Time
We strongly recommend that you install and upgrade your apps during off-peak hours or scheduled maintenance windows. There are known issues in the Jira plugin infrastructure that may cause performance degradation and impede app installation when your Jira instance is under heavy load.
Installing Structure
If your Jira server does not have Structure yet, the installation is simple:
- Download and install Structure app, either from the Atlassian Marketplace or our Download page.
- When Add-on Manager reports the successful installation, click Get Started to visit a page with important guidance for the Jira administrator. You may want to also check out the user's Get Started page, available under the "Structure" top-level menu.
- Monitor
catalina.outorjira-application.logfor log messages from Structure.
Upgrading Structure
The upgrade procedure from versions 3.0–5.6 is simple:
- Consider backing up Jira data. Use Administration | System | Backup System. (If you have a large instance and a proper backup strategy in place, you may skip this step.)
- Back up Structure data. Use Administration | Structure | Backup Structure menu item. If you have a lot of structures and a large Jira, consider turning off the "Backup History" option to avoid a long backup process.
Install the new version of the plugin.
- Monitor
catalina.outorjira-application.logfor warnings or errors.
Upgrading from Structure 2.9–2.11
If you have a Structure version older than 2.9, please upgrade to Structure 2.11.2 version first.
Starting with version 6.0, Structure is no longer able to access the old Structure 2.x database, but old backup files are still supported. Therefore, you'll need to back up your Structure 2.x data before upgrading. The recommended upgrade procedure is as follows:
- While still running the old version of Structure, go to Administration | Structure | Structure Backup and create a backup of the current Structure data.
- Download and install Structure 6.0, either from the Atlassian Marketplace or our Download page.
- When the Add-on Manager reports the successful installation, click Get Started to visit a page with important guidance for the Jira administrator. You may want to also check out the Structure Quick Start Guide.
To transfer your data, go to Administration | Structure | Restore Structure and use the Structure 2.x backup made earlier.
- Monitor
catalina.outorjira-application.logfor log messages from Structure.
Enterprise Deployment Notes
Structure 6.0 is a major release with a lot of changes in the attribute system and an important new feature, effectors.
Changes to the Attribute System
In Structure 6.0 we have largely rewritten the attribute system, which is a crucial part of Structure, responsible for displaying all values that you see in columns inside the Structure grid, including issue field values, aggregates, and formulas. We have run extensive performance tests internally, and we are pretty sure that the new attribute system performs no worse than the old one, and significantly better in many cases.
However, we still advise you to perform load- and stress-testing on a staging environment before you upgrade, especially if you rely on aggregates and complex formulas, or export large structures to printable and Excel formats.
Effectors
Effectors are a completely new feature, and they shouldn't affect the performance of the rest of the product. However, effectors were a pretty popular feature request, and we expect their wide adoption. If you already have a potential use case for effectors in your organization, we advise you to try them on a staging system before upgrading.
Using effectors can put a noticeable load on the system, because running an effector, especially on a large structure, could require a lot of issues to be loaded from the database, and then updated. Because of that, we designed effectors so that they do not run automatically; instead, they have to be controlled manually by Structure users. Effectors always operate on behalf of the user who runs them, and all the necessary permissions are checked as if that particular user were trying to make the changes.
Access to Effectors
By default, any user who has the "Access Automation" global Structure permission will be able to add effectors to their structures, and any user with the "Bulk Change" global Jira permission will be able to run previously-installed effectors. If you prefer a gradual roll-out, you can limit users' access to effectors as described in Changing Permissions to Configure and Run Effectors.
Effector Execution
Running an effector is a two-step process. First, a preview is generated, listing all the changes that the effector is going to make. Then, if the user approves the preview, those changes are actually made, in a separate background process.
To calculate effector previews, Structure uses a separate thread pool (in a Data Center environment, on each node), so several previews can be calculated in parallel. By default, the effector thread pool is limited to N+1 threads, where N is the number of available processor cores. You can change the maximum size of the thread pool by setting the "structure.jobManager.effectorThreads" dark feature.
In contrast to preview calculation, effectors never update issues in parallel. If several users want to make changes using effectors, their requests are queued and processed one-by-one. In a Data Center environment, a single node is responsible for making the changes. If that node leaves the cluster, a different node picks up this responsibility, continues the current task from where it stopped, and takes the next task from the queue.
New Database Tables
There are three new tables in the database schema to store the data related to effectors.
The AO_8BAD1B_EFFECTOR_INSTANCE table stores effector parameters. A new row is created each time a user adds an effector to a structure. The data from this table is exported when you back up Structure data and can be migrated to a different instance. The table is also exported along with all Structure data during Jira backup.
The AO_8BAD1B_EFFECTOR_PROCESS table stores current and past effector runs. There is one row per process, regardless of how many effectors are run. When a preview is calculated, it is also stored in this table, and deleted when all changes are applied. Effector runs are not backed up by Structure, but the table is exported during Jira backup.
The AO_8BAD1B_EFFECTOR_RECORD records all changes made by effectors, and how to undo them. There is one row for each update attempt, successful or not. This data is not backed up by Structure, but the table is exported during Jira backup.
There is a new maintenance task that deletes old effector processes and their changes. By default, finished effector processes and their changes are kept for 30 days, and unfinished processes that didn't make any changes are kept for 24 hours. For more information on automatic maintenance please refer to the documentation.